
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- x64dbg
- 악성코드
- 러시아
- 랜섬웨어
- 블랙바스타
- 릭 릭스비
- 부다페스트 협약
- 오픈소스 관리체계
- 사이버안보 협약
- 디지털 증거의 증거능력
- 랜섬웨어 분석
- Black Basta
- 악성코드 분석
- 보안사고 회고
- 독서
- Malware Tool
- 국제 사이버 범죄
- 분석
- 악성코드분석
- CISO 제도 분석
- 오래된 지혜
- Fileless
- CAN Network
- 사이버안보
- VirtualAddress
- 오픈체인
- 우크라이나
- 판례평석
- MALWARE
- L:azarus
- Today
- Total
봔하는 수달
CAN Network 이상탐지 본문
CAN 네트워크란?
- 1980년대 독일의 Bosch 사에서 차량 내 ECU들의 양방향 통신을 지원하기 위해 설계된 'serial bus' 통신 방식
- 차량, 항공기, 산업용 제어기 등 다양한 곳에서 사용되며 차량 보안에서 주요한 쟁점
다양한 필드등이 존재하며 필드가 포함하는 정보는 아래와 같다.
| SOF | Arbitration Field | Control Field | Data Field | CRC Sequence | DEL | ACK | DEL | EOF | ITM |
SOF(Start Of Frame) : 메시지의 처음을 지시하고 동기화를 위해 사용됨.
Arbitration Field : 중재 필드로서 11비트 또는 29비트의 크기를 갖으며 메시지간의 충돌을 조정하는 역할을 수행.
Control Field : 2비트의 IDE(IDentifier Extension) 비트와 4비트의 데이터 길이 코드를 구성
Data Field : 8byte 까지 사용 가능하며, 데이터를 저장하는 데 사용
이후 필드는 학습에 사용되지 않았기 때문에 본문에서는 자세히 다루지 않습니다.
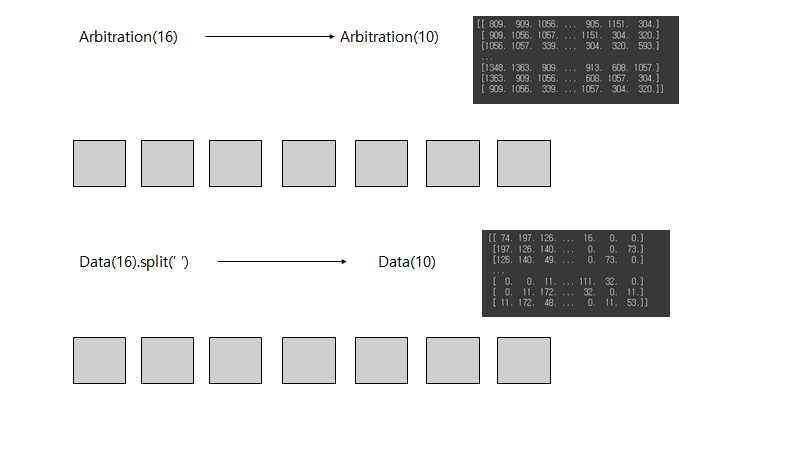
학습은 HMM을 이용한 비지도학습으로 진행되었으며, 학습에 사용된 데이터는 Arbitration Field와 Control Field이다.
코드 정보는 아래 링크!
https://github.com/SH112-kr/ICS_CAN_HMM
GitHub - SH112-kr/ICS_CAN_HMM: HMM을 통한 CAN 네트워크 이상탐지
HMM을 통한 CAN 네트워크 이상탐지 . Contribute to SH112-kr/ICS_CAN_HMM development by creating an account on GitHub.
github.com
예제 코드 속도 개선
학습을 위해 제공 받았던 예제 코드를 돌리는 과정에서 속도가 상당히 느리다고 생각을 하여 어느정도 개선이 필요하다고 판단하여 개선을 진행하였다.
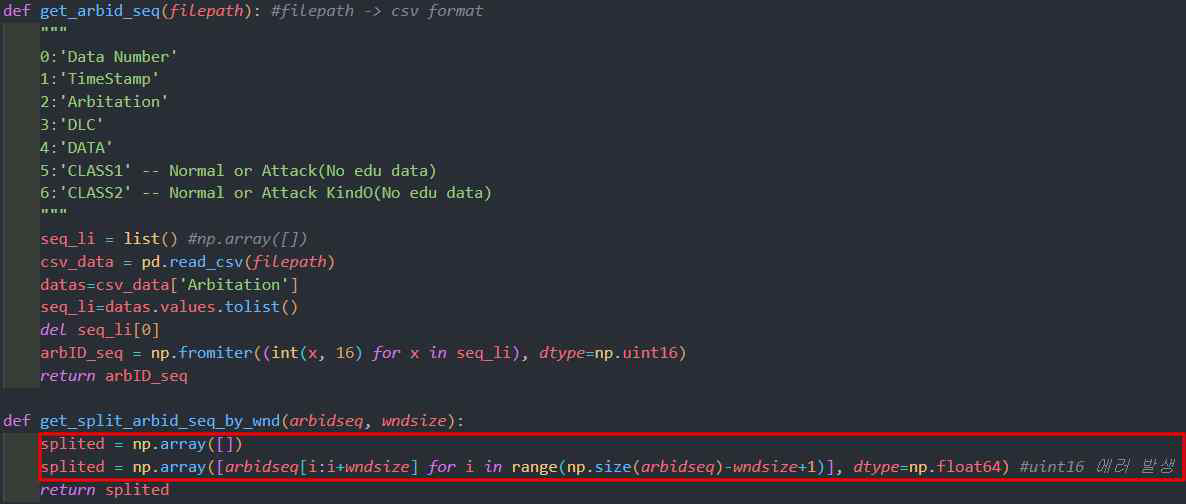
기존 예제 코드를 분석해보면 처음 반복문을 통해서 리스트에 모든 시퀀스를 담은 뒤 담겨진 리스트를 ‘reshape’를 통해서 분할을 하게 된다. 메모리에 모든 데이터가 올려진 상태로 해당 데이터를 가공하게 되면 속도와 자원 측면에서 낭비가 있기 때문에 이 2개의 과정을 반복문 과정에서 범위지정을 통해 슬라이딩하여 넣어주게 되면 시간과 자원의 낭비를 줄일 수 있다.

개선을 진행하게 되면 아래와 같은 동작으로 진행하게 된다.
데이터 특징 분석
공격의 유형으로는 크게 4가지로 Flooding, Spoofing, Fuzzing, Replay 가 있고 육안으로 데이터를 봤을때 유의미한 데이터 패턴을 가진 공격 유형은 Flooding, Spoofing, Fuzzing 이 있다.
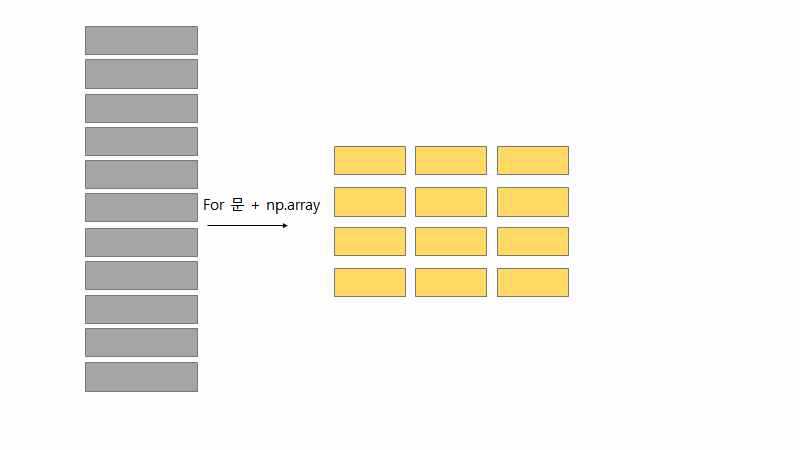
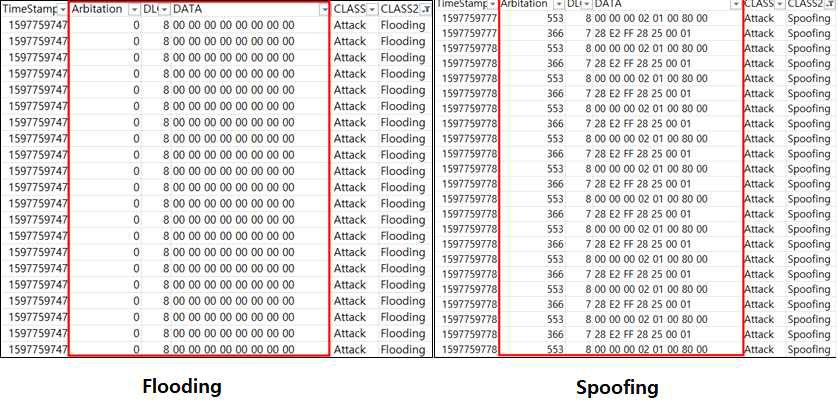
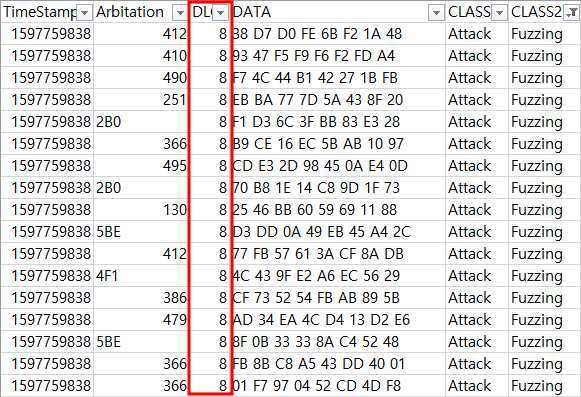
Flooding 공격 데이터의 특징
Flooding 공격의 특징은 Arbitration 필드의 값이 0으로 고정되어있고 DATA의 값이 모두 00 으로
도배가 되어있다는 특징이 있다. 또한, 컨트롤 필드 또한 8로 도배되어있다.
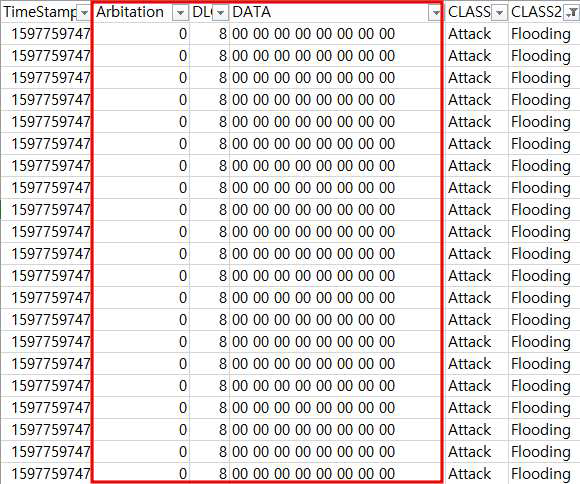
Spoofing 공격 데이터의 특징
Spoofing 공격의 특징으로는 Arbitration 필드가 553 -> 366 -> 553을 반복한다는 특징이 있고
Control 필드의 경우 8 -> 7 ->8을 반복한다는 특징이 있다. 또한, Data 필드는 ‘00 00 00 02 01
00 80 00’ -> ‘28 E2 FF 28 25 00 01’를 반복한다.
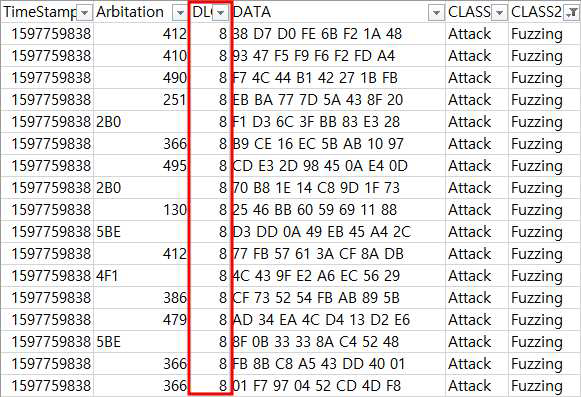
Fuzzing 공격 데이터의 특징
Fuzzing 공격의 특징으로는 임의의 값을 계속 Fuzzing 하기 때문에 공격자가 DLC를 모두 8로
채웠다는 특징이 존재했다. (다만, 이건 공격자의 입장에서 대응하기 쉬운 특징)
HMM 모델 파라미터 실험
Window Size
윈도우 사이즈의 경우 적절한 슬라이딩 크기를 찾기 위해 최초 반복문을 통해서 그 수를 조정해주며
1~1000까지의 범위를 실험해 가며 테스트를 조정하고자 함. 그러나 학습을 진행하는 Colab 환경에서
개인당 할당한 자원을 모두 소비하여 GPU 자원을 더 이상 사용 못하게되어 실험과정에서 1칸씩
늘리는건 의미가 없다고 판단하여 슬라이딩 증가 범위를 조정하여 아래와 같이 조정함.
windowsize = [5 ,50 ,100 ,200 ,300 ,400 ,500 ,600 ,700 ,800 ,900 ,1000
| ------------------------------------------------------------ Training log : -6262971.255425339 Test log : -29080828.653945256 윈도우 사이즈 5 의Traing log 와 Test log의 거리 : 22817857.39851992 이전 거리와의 차이 22817857.39851992 초기 상태 확률 : [0.07616607 0.92383393] 전이 확률 행렬 : [[0.91720501 0.08279499] [0.15981611 0.84018389]] ------------------------------------------------------------ Training log : -63529291.78915628 Test log : -295059841.54828525 윈도우 사이즈 50 의Traing log 와 Test log의 거리 : 231530549.75912896 이전 거리와의 차이 208712692.36060905 초기 상태 확률 : [1.00000000e+00 1.41308707e-83] 전이 확률 행렬 : [[0.9151413 0.0848587 ] [0.08401708 0.91598292]] ------------------------------------------------------------ Training log : -127089823.82924558 Test log : -590240992.2417345 윈도우 사이즈 100 의Traing log 와 Test log의 거리 : 463151168.41248894 이전 거리와의 차이 231620618.65335998 초기 상태 확률 : [1.00000000e+00 8.67117955e-86] 전이 확률 행렬 : [[0.91715368 0.08284632] [0.0841264 0.9158736 ]] ------------------------------------------------------------ Training log : -254260918.6375899 Test log : -1180092764.1609187 윈도우 사이즈 200 의Traing log 와 Test log의 거리 : 925831845.5233288 이전 거리와의 차이 462680677.11083984 초기 상태 확률 : [2.47051762e-103 1.00000000e+000] 전이 확률 행렬 : [[0.91737475 0.08262525] [0.08404308 0.91595692]] ------------------------------------------------------------ Training log : -381445950.97099733 Test log : -1769158579.7146661 윈도우 사이즈 300 의Traing log 와 Test log의 거리 : 1387712628.7436688 이전 거리와의 차이 461880783.22034 초기 상태 확률 : [1.81772507e-113 1.00000000e+000] 전이 확률 행렬 : [[0.91662512 0.08337488] [0.08322582 0.91677418]] ------------------------------------------------------------ Training log : -508530282.00382566 Test log : -2357911470.439504 윈도우 사이즈 400 의Traing log 와 Test log의 거리 : 1849381188.4356785 이전 거리와의 차이 461668559.6920097 초기 상태 확률 : [1.00000000e+00 6.27599855e-79] 전이 확률 행렬 : [[0.91670112 0.08329888] [0.08326862 0.91673138]] ------------------------------------------------------------ Training log : -635389633.7916285 Test log : -2946854011.2392764 윈도우 사이즈 500 의Traing log 와 Test log의 거리 : 2311464377.447648 이전 거리와의 차이 462083189.01196957 초기 상태 확률 : [7.9734731e-301 1.0000000e+000] 전이 확률 행렬 : [[0.91667441 0.08332559] [0.08319344 0.91680656]] ------------------------------------------------------------ Training log : -761959940.551307 Test log : -3536688099.6161885 윈도우 사이즈 600 의Traing log 와 Test log의 거리 : 2774728159.0648813 이전 거리와의 차이 463263781.6172333 초기 상태 확률 : [1.00000000e+000 4.41655911e-237] 전이 확률 행렬 : [[0.91684675 0.08315325] [0.08338333 0.91661667]] ------------------------------------------------------------ Training log : -888436502.1298738 Test log : -4125913110.9582314 윈도우 사이즈 700 의Traing log 와 Test log의 거리 : 3237476608.8283577 이전 거리와의 차이 462748449.7634764 초기 상태 확률 : [0. 1.] 전이 확률 행렬 : [[0.91682823 0.08317177] [0.08337905 0.91662095]] ------------------------------------------------------------ Training log : -1014871894.9954238 Test log : -4714516334.332136 윈도우 사이즈 800 의Traing log 와 Test log의 거리 : 3699644439.3367124 이전 거리와의 차이 462167830.50835466 초기 상태 확률 : [0. 1.] 전이 확률 행렬 : [[0.91674345 0.08325655] [0.08326051 0.91673949]] ------------------------------------------------------------ Training log : -1141188458.614821 Test log : -5302926528.692997 윈도우 사이즈 900 의Traing log 와 Test log의 거리 : 4161738070.078176 이전 거리와의 차이 462093630.74146366 초기 상태 확률 : [1. 0.] 전이 확률 행렬 : [[0.91667632 0.08332368] [0.08318397 0.91681603]] ------------------------------------------------------------ Training log : -1267312839.9995592 Test log : -5891525826.117831 윈도우 사이즈 1000 의Traing log 와 Test log의 거리 : 4624212986.118272 이전 거리와의 차이 462474916.0400958 초기 상태 확률 : [0. 1.] 전이 확률 행렬 : [[0.91656732 0.08343268] [0.08307814 0.91692186]] ------------------------------------------------------------ |
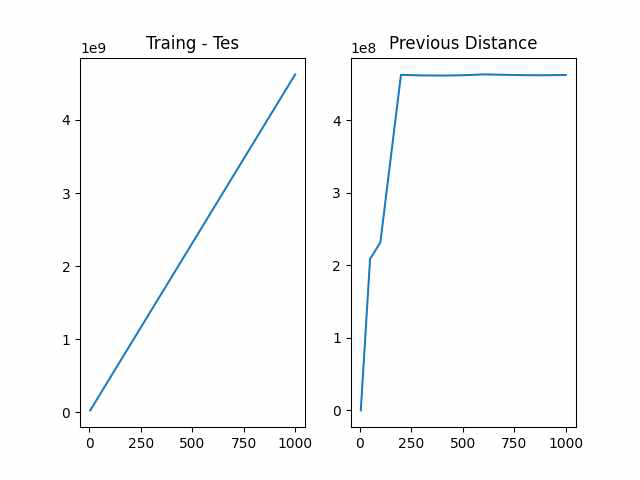
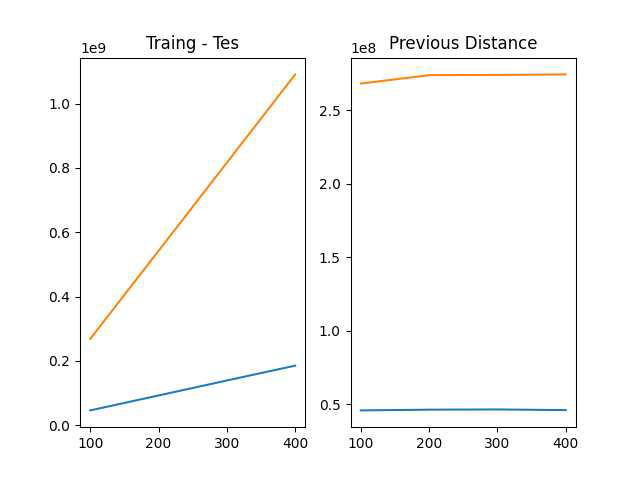
Window Size 실험 고찰
해당 위의 데이터에서 Window 사이즈를 조절해가며 확인해본 결과 Train 데이터와 Test 데이터의
차이는 왼쪽 그래프처럼 계속 거리가 멀어지는 양상을 보였고 좀 더 효율적인 부분을 찾기 위해 앞선
증가량의 비율을 그래프로 표시해본 결과 Previous Distance 그래프와 같은 양상을 보였다. 최초
본인이 생각한 그래프 양상은 지속해서 상승하다가 거리 증가량이 어느 정도 안정화되어 Previous
Distance가 0에 가까워지는 예측을 했는데, 1000개의 슬라이딩으로는 부족하다는 판단이 되었다.
그리하여 이를 개선하기 위해 슬라이딩을 좀 더 넓게 잡아보려 하였으나. Colab 환경이 RAM을
12.9GB가 한계가 있어 동작이 불가능하였다.
Hidden State 실험
Hidden State의 경우 2개의 경우 악성과 정상의 케이스를 분류하는 것으로 추정되며 이후 경우의
수를 좀 더 확인하기 위해 2, 3, 4, 5 순서로 100의 Window 사이즈로 실험을 진행하였다.
| ------------------------------------------------- Training log : -127089823.82924558 Test log : -590240992.2417345 윈도우 사이즈 100 의Traing log 와 Test log의 거리 : 463151168.41248894 이전 거리와의 차이 231620618.65335998 초기 상태 확률 : [1.00000000e+00 8.67117955e-86] 전이 확률 행렬 : [[0.91715368 0.08284632] [0.0841264 0.9158736 ]] ------------------------------------------------- Training log : -126602482.19212367 Test log : -591995756.2091084 윈도우 사이즈 100 의Traing log 와 Test log의 거리 : 465393274.0169847 이전 거리와의 차이 465393274.0169847 초기 상태 확률 : [2.78913802e-115 2.98295783e-138 1.00000000e+000] 전이 확률 행렬 : [[8.74466082e-01 1.25533874e-01 4.38482638e-08] [1.23445948e-05 8.74622345e-01 1.25365310e-01] [1.24716610e-01 2.90529706e-05 8.75254337e-01]] ------------------------------------------------- Training log : -126294692.63730867 Test log : -592882879.8478078 윈도우 사이즈 100 의Traing log 와 Test log의 거리 : 466588187.2104991 이전 거리와의 차이 466588187.2104991 초기 상태 확률 : [1.91543104e-184 6.59228584e-227 2.43711038e-090 1.00000000e+000] 전이 확률 행렬 : [[8.40222548e-01 4.72577798e-04 1.52092549e-01 7.21232479e-03] [1.71205714e-01 8.28431611e-01 2.47777769e-12 3.62674937e-04] [3.77611679e-04 2.04478935e-19 8.06781270e-01 1.92841118e-01] [1.30963432e-03 1.41814898e-01 1.95867635e-04 8.56679600e-01]] ------------------------------------------------- Training log : -126098814.84522334 Test log : -587805009.9707693 윈도우 사이즈 100 의Traing log 와 Test log의 거리 : 461706195.125546 이전 거리와의 차이 461706195.125546 초기 상태 확률 : [1.00000000e+000 1.61658603e-267 2.15834987e-099 0.00000000e+000 3.48790526e-131] 전이 확률 행렬 : [[8.23307753e-01 1.42928009e-01 3.37642379e-02 4.76591099e-15 2.57819722e-30] [5.67748711e-35 8.18248194e-01 5.20211115e-02 1.29730694e-01 1.67699203e-34] [1.80848941e-02 1.81602450e-02 9.02316865e-01 3.43241147e-02 2.71138812e-02] [3.18777143e-40 1.80403161e-33 4.21756965e-02 8.08264315e-01 1.49559989e-01] [1.51595051e-01 3.85906555e-34 2.85014883e-02 7.02953599e-33 8.19903461e-01]] ------------------------------------------------- |
Hidden State 실험 고찰
Arbitration으로 실험을 했을 때 앞서 데이터 분석을 했을 때 Arbitration 단일로 유의미한
결과가 나온 공격 타입은 2가지(Flooding, Spoofing) 공격이었다.
고로 가장 유의미한 데이터를 내포하고있는 Hiddent State 2와 3은 각각 Attack, Normal &
Normal, Flooding, Spoofing 일 것이라고 예상된다.
| Hiddent State(2) | Normal | Attack |
| Normal | 0.91715368 | 0.08284632 |
| Attack | 0.0841264 | 0.9158736 |
| Hiddent State(3) | Normal | Attack(1) | Attack(2) |
| Normal | 8.74466082e-01 | 1.25533874e-01 | 4.38482638e-08 |
| Attack(1) | 1.23445948e-05 | 8.74622345e-01 | 1.25365310e-01 |
| Attack(2) | 1.24716610e-01 | 2.90529706e-05 | 8.75254337e-01 |
한계점 및 개선점
Arbitration 단일로만 공격을 판단하기에는 공격의 종류 중 Fuzzing과 Replay 공격의 경우에는Arbitration으로만 탐지하기에는 어려움이 존재한다. 다만 Fuzzing의 경우에는 DLC의 값이 8이라는특징이 있어서 이를 활용하면 탐지할 수 있으리라 판단할 수도 있지만, 이건 공격자의 관점에서Fuzzing을 효율적으로 하기 위해 값을 가득 채워서 보냈을 뿐 공격자가 이를 인지하고 필드 값을무작위로 보내면 우회할 수 있다는 단점이 존재한다. 또한, TIMESTAMP 를 통해서 연속적으로 공격이
들어오면 판단할 수 있는가? 라는 생각도 할 수 있지만 이건 상태 천이도를 볼 때 Normal도 마찬가지로 연속적으로 진행되기 때문에 그렇게 의미 있는 데이터라고 판단이 되지 않는다.
다만, 해당 모델을 사용해서 탐지하게 된다면 Flooding과 Spoofing의 공격에 대한 탐지에서는 효과적이라고 판단할 수 있어, Defence in Depth 형태로 일반 보안 장비 앞단에서 어느 정도 패킷을 걸러내어 복합적으로 동작한다면 효과적이라고 판단이 된다.
시퀀스 효율 분석
앞서 공격 데이터를 분석해본 결과 학습 데이터로서 유의미한 결과를 가질 수 있을 값들은 Arbitration과 Data 필드의 값이었다. 그리하여 해당 장에서는 Arbitration과 Data 필드의 값을 같은 방식으로 가공하고 같은 방식으로 학습을 진행하여 Train 데이터와 Test 데이터의 차이 및 윈도우 사이즈 별 거리 증가율을 비교 분석해보았다. 그 결과 같은 조건일 때 데이터 필드로 학습한 모델이 성능이 더 우수하게 나온 것으로 확인되었다.
'개발' 카테고리의 다른 글
| [코테] if 조건문 or 연산에서 주의점 (0) | 2023.04.04 |
|---|---|
| 악성 APK 디텍터 개발 일지 (1) | 2022.07.16 |